Useful tips for AWS Lambda and DynamoDB in Go

Use Query instead of Scan#
Dont…Ever…Use…Scan…in DynamoDB. Seriusly, dont!
A scan is the most brutal operation that returns all data, even if you use Filter. The logic behind Scan is that scans the whole table AND THEN applies the filter. Not only it’s slow, but your consumed capacity will always be high meaning, you will not like what you see on AWS Bill.
Well, why is there a Scan operation in SDK if it’s slow and costly?
For example, let’s take some data and see where scan is useful.
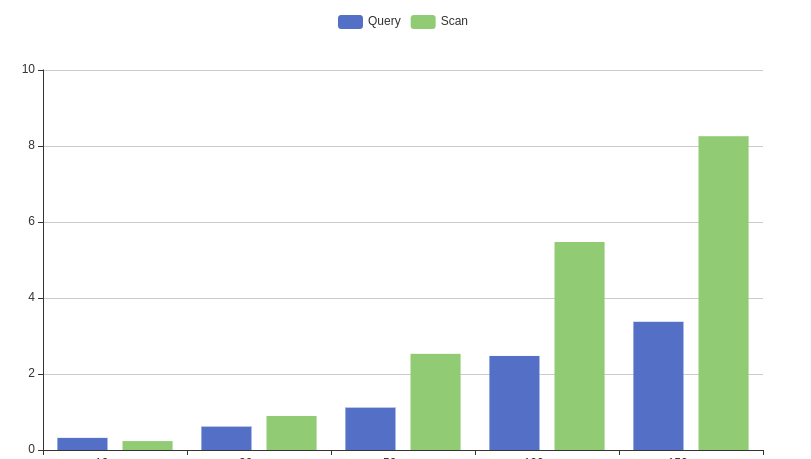
Scan works faster on small data (eg if you have a small table to store configs) and it’s cheap(!for small amount of data) compared to Query with index. Also, if you plan to migrate or take all data, Scan be also useful here as you are requesting all data.
TLDR; use Query
Compress response from DB#
The new aws-sdk-go-v2 accepts options parametars when creating a new DynamoDB client.
One of those options is EnableAcceptEncodingGzip which is disabled by default.
dynamodb.NewFromConfig(cfg, func(o *dynamodb.Options) {
o.EnableAcceptEncodingGzip = true
})
This will help you to squeeze some milliseconds when data is returned.
Use goroutines more#
This is more related to go language, but in most projects, I see something like this:
f1 := fetchThis()
f2 := fetchThat()
f3 := fetchOther()
// combine and do some calculation
calculate(f1,f2,f3)
If you need to do multiple things independently - use goroutines! An exellect package errgroup provides synchronization, error propagation, and Context cancelation for groups of goroutines working on subtasks of a common task.
data := struct {
sync.Mutex
in []int
}{}
group, ctx := errgroup.WithContext(ctx)
group.Go(func() error {
f1, err := fetchThis()
if err != nil {
return err
}
data.Lock()
data.in = append(data.in, f1...)
data.Unlock()
return nil
})
group.Go(func() error {
f2, err := fetchThat()
if err != nil {
return err
}
data.Lock()
data.in = append(data.in, f2...)
data.Unlock()
return nil
})
// ....
if err := group.Wait();err!= nil {
return err
}
Implement caching#
If you have a lambda that gets triggered a lot of time and this lambda needs to call multiple sources (DB, API, etc) and most of the time it returns the same amount of data, it’s time to implement a cache.
A sample cache DynamoDB store can be implemented like this:
package store
// Get returns the cache for the given key.
func (c *cacheStore) Get(ctx context.Context, key string) (*Cache, error) {
out, err := c.db.GetItem(ctx, &dynamodb.GetItemInput{
TableName: aws.String(c.tableName),
Key: map[string]types.AttributeValue{
"CacheKey": &types.AttributeValueMemberS{Value: key},
},
})
if err != nil {
return nil, errors.Wrap(err, "error sending DB query request")
}
if len(out.Item) == 0 {
return nil, nil
}
cache := new(Cache)
err = attributevalue.UnmarshalMap(out.Item, cache)
if err != nil {
return nil, errors.Wrap(err, "error unmarshaling DB result")
}
return cache, nil
}
// Set sets the cache for the given key.
func (c *cacheStore) Set(ctx context.Context, cache *Cache) error {
_, err := c.db.PutItem(ctx, &dynamodb.PutItemInput{
TableName: aws.String(c.tableName),
Item: map[string]types.AttributeValue{
"CacheKey": &types.AttributeValueMemberS{Value: cache.Key},
"CacheValue": &types.AttributeValueMemberB{Value: cache.Value},
},
})
return err
}
Now in our middleware, we can use this store to get/set cached values.
In my case, I use the input as a key (input can be a URL + query or just query)
key := sha256.Sum256(input)
Did you notice something missing?
Yes - where is the remove method?
- No WRITE THROUGHPUT
- No COST
There is no need to re-implement cache expiry. DynamoDB can handle that for us.
Note
DynamoDB value cannot exceed 400KB! So if your cache value is greater, you will encounter Put error.
Check the size before deciding to store in DB.
For this type of large objects, it’s best and cheaper to use S3 storage.
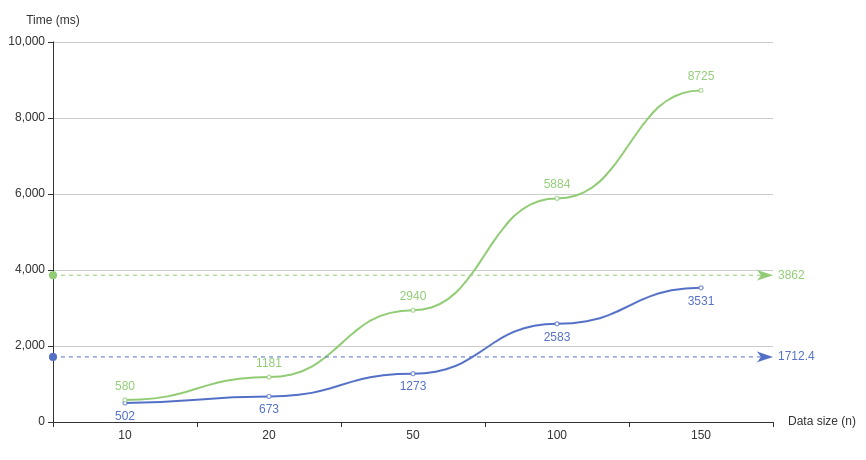
End results#
It’s not a lot, but doing these small non-breaking changes, we can see optimization.
- Green - old, with Scan, without compression and goroutines
- Blue - new, with Query, with compression and goroutines